How AI Сhanged What CTOs Ask Us To Hire: Data From 30+ Product Companies
26 min
· April 16, 2026

Two years ago, our intake calls with CTOs followed a predictable script. They needed backend engineers, a couple of frontend developers, maybe a DevOps person. The conversation lasted 20 minutes, sometimes less.
That script broke around mid‑2024. One CTO opened a call asking for “someone who can build data pipelines and also understands transformer architectures.” Another wanted “an ML engineer, but one who’s done production work, not Kaggle.” A third admitted they’d been trying to hire a senior ML engineer for five months and hadn’t made a single offer.
Newxel works with over 30 product companies across the globe to build engineering teams through our hiring hubs across Eastern Europe. What follows is a synthesis of the hiring patterns we’ve tracked across those engagements since 2022, and what they tell us about where AI adoption is heading operationally.
This matters for a practical reason. 82% of organizations have increased international AI hiring, according to Deel’s 2026 global hiring report. The talent concentration that used to make San Francisco, New York, London, and Tel Aviv the obvious places to build AI teams has become a cost and competition problem rather than an advantage. CTOs who built their last engineering team in one metro are now building their AI capability across three time zones. They’re doing it with job descriptions that would’ve been unrecognizable to their 2022 selves.
What changed isn’t just the list of roles. It’s the sequencing, the skill expectations inside familiar titles, the team structures, the time‑to‑hire benchmarks, and the geographic strategy. This article works through all of that, based on what we’ve seen in our data rather than what the market is claiming. Our intake calls now run 45 minutes. They cover data infrastructure readiness, existing MLOps tooling, and whether the company has ever deployed a model to production before.
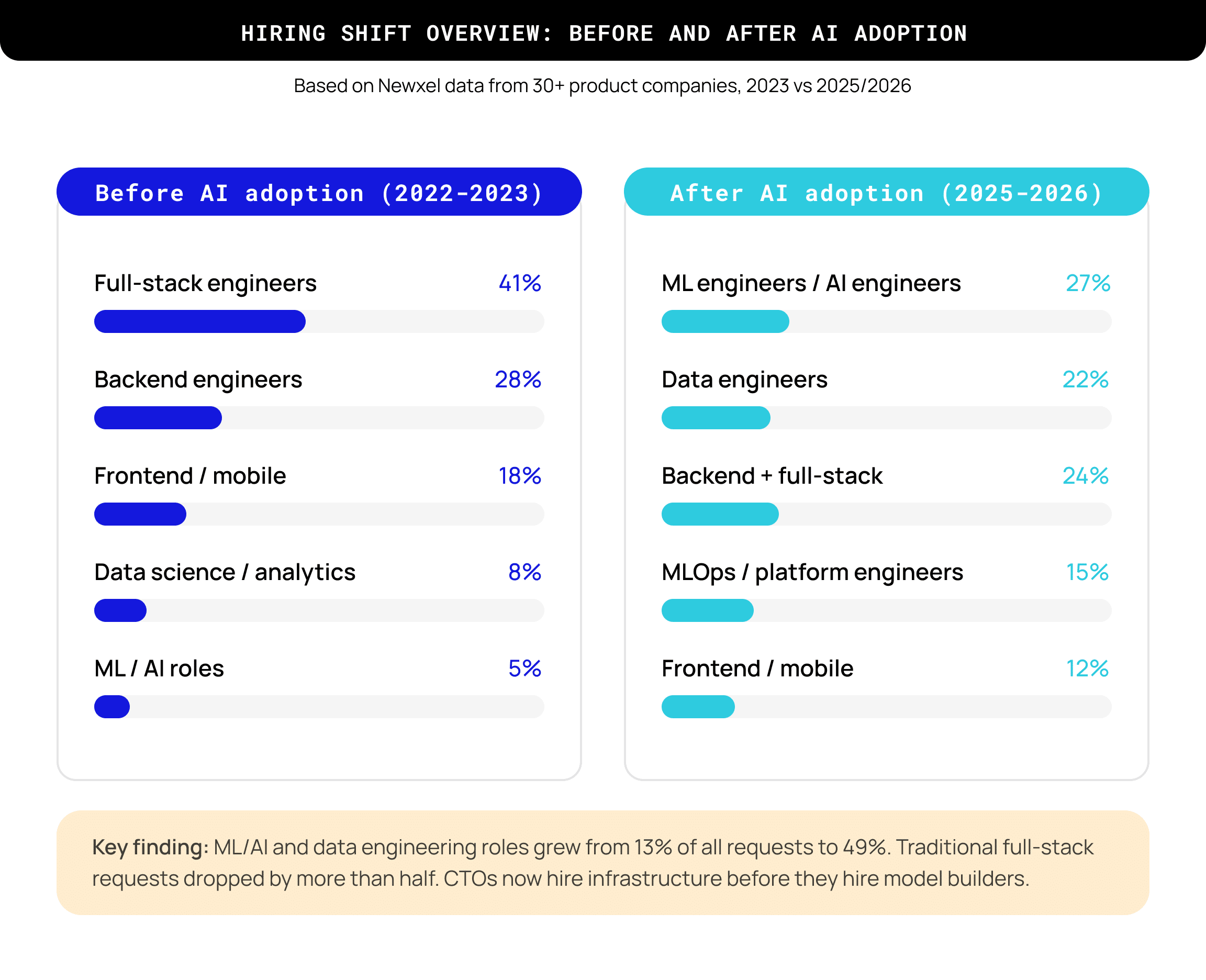
Between 2022 and early 2024, around 69% of all hiring requests we received were for traditional software engineering work: full‑stack, backend, frontend, and mobile. Data science and ML together made up roughly 13% of requests, and most of those were analytical roles rather than production engineering.
By the second half of 2025, that ratio had flipped. ML engineers, data engineers, and MLOps specialists now account for close to half of all incoming requests. Full‑stack has dropped to about 24%. Traditional backend and frontend requests haven’t disappeared, though they’ve become a smaller share of a larger total volume.
The shift didn’t happen gradually. It arrived in two distinct waves. The first came in late 2023, when CTOs started asking for data engineers to “get the house in order” before building AI features on top of it. The second came in early 2025, when companies that had spent a year experimenting with LLMs realized they needed ML engineers who could deploy and monitor models in production, not just train them in notebooks.
Robert Half’s 2026 technology job market report reflects a parallel pattern at the market level: AI, ML, and data science roles totaled 49,200 US postings in 2025, a 163% increase over 2024. Most of that growth sits in production and infrastructure roles, a detail that often gets lost when people quote aggregate AI hiring numbers. Companies aren’t hiring researchers at the rate the headlines suggest. They’re hiring engineers who make research usable.
If you look at the specific titles in our 2025 and 2026 hiring requests, a clear hierarchy appears. Four role categories do most of the work.
ML engineers with production experience top the list. These aren’t people building models in notebooks and handing them off. CTOs want engineers who’ve taken models through the full lifecycle: training, validation, deployment, monitoring, retraining, and retiring. The day‑to‑day looks less like research and more like platform engineering with an ML shape. When we screen for this role, we’re looking for candidates who can discuss model drift by name, who’ve used experiment tracking tools like MLflow or Weights & Biases in anger, and who’ve argued with a data engineer about schema contracts at least once. The strongest candidates we place come out of Kyiv, Krakow, and Bucharest, where the applied ML community has matured faster than most foreign CTOs realize.
Data engineers come second, and this surprised us. Before AI adoption, data engineering requests were rare among product companies. Now, CTOs have learned through expensive experience that you can’t build AI features on messy data. One client told us, after four months of failed fine‑tuning attempts, that they’d finally understood their training data was garbage and they should’ve hired a data engineer first. We’ve repeated that sentence back to half a dozen other CTOs since. The data engineer’s job, from an AI readiness standpoint, is to build the pipelines, transformations, and quality checks that make ML work possible. That requires deep SQL skill, distributed computing experience with tools like Spark, Airflow, and dbt, and enough software engineering discipline to write testable, maintainable code. This profile exists in strong supply across our Polish and Romanian hubs.
MLOps engineers are third, and the demand has grown faster than any other category in our data. LinkedIn’s 2025 MLOps data showed 9.8x growth in the role over five years. In our own intake, this title barely existed before 2024. Now we’re placing MLOps engineers every month. The role sits at the intersection of DevOps and ML: managing model deployment infrastructure, building CI/CD pipelines for ML workflows, maintaining feature stores, handling GPU orchestration, and setting up monitoring that catches silent model failures. Experienced DevOps engineers from our Ukrainian and Bulgarian hubs often transition into MLOps after picking up ML‑specific tooling such as Kubeflow, Seldon, Feast, and Ray. The compensation premium over traditional DevOps is significant, which helps retention.
LLM integration engineers are newer still, and the role is still stabilizing. These are people who work with large language model APIs, fine‑tuning workflows, RAG (retrieval‑augmented generation) architectures, and production‑level prompt engineering. One industry analysis found LLM engineering skills appeared in just 3% of data science job listings in early 2025, jumping to 12% by early 2026. Our own intake confirms the trajectory. The challenge with this role is that “LLM engineer” means something different at almost every company. Some want a backend engineer who can integrate OpenAI and Anthropic APIs and write reliable prompts. Others want a research‑adjacent engineer who can fine‑tune open‑weight models on proprietary data. We spend more scoping time on this role than any other.
Salary ranges across these four categories vary by region, experience, and sub‑specialty, but a few benchmarks are worth anchoring to. A senior ML engineer in San Francisco runs $220,000 to $340,000 in total compensation (base, bonus, equity), per Glassdoor and Levels.fyi data from late 2025 and early 2026. Once you add employer payroll taxes, benefits, recruiter fees, office overhead, and equipment, fully loaded cost lands in the $280,000 to $420,000 range. The same profile in Eastern Europe, hired through our staff augmentation model, lands in the $80,000 to $120,000 annual range for the client, all‑in. MLOps sits 10 to 15% below ML engineer compensation in both geographies. Data engineer compensation runs another 10 to 15% below MLOps. The spread between US and Eastern European pricing is narrower for these roles than for traditional engineering, because AI skill demand has compressed the global market, though the absolute savings remain material at the team level.
Something odd is happening in job descriptions. They’re getting longer. They’re also blending disciplines that used to sit in separate teams.
We see CTOs ask for “a data engineer who understands ML pipelines,” “a backend developer who can integrate LLM endpoints and manage vector database scaling,” or “a DevOps engineer who’s worked with GPU clusters and model serving infrastructure.” These are hybrid roles, and they don’t map cleanly to traditional job titles or to the way universities train engineers.
The production versus research gap is driving this. Academic ML programs produce generalists who know how to build models. Industry needs people who can also containerize those models, monitor their performance in production, handle drift, retrain on new data, and explain the whole thing to a product manager. A 2025 analysis of more than 1,000 ML job postings found that 57.7% of employers preferred domain experts over generalists, which is a polite way of saying that “generalist ML engineer” has stopped being a useful category for most hiring managers.
Stanford’s AI Index has tracked the migration of AI PhDs from academia to industry. By 2022, 70.7% of newly graduated AI PhDs went straight into industry work, up from roughly 41% in 2011. These candidates enter the workforce with research skills, and many lack the engineering fundamentals for production work. Companies end up asking for both skill sets in one person, which creates job descriptions that are essentially impossible to fill at market rate. We often spend the first intake call helping a CTO split a single impossible role into two realistic ones.
The time‑to‑hire gap between AI and traditional engineering roles is dramatic. In our data, senior ML engineers take an average of 85 days to place, compared to 28 days for a full‑stack engineer. MLOps engineers average 75 days. Data engineers with AI‑focused experience take around 65 days. For a CTO who’s used to filling a backend role in a month, the first AI hire can feel like watching a slow‑motion failure.
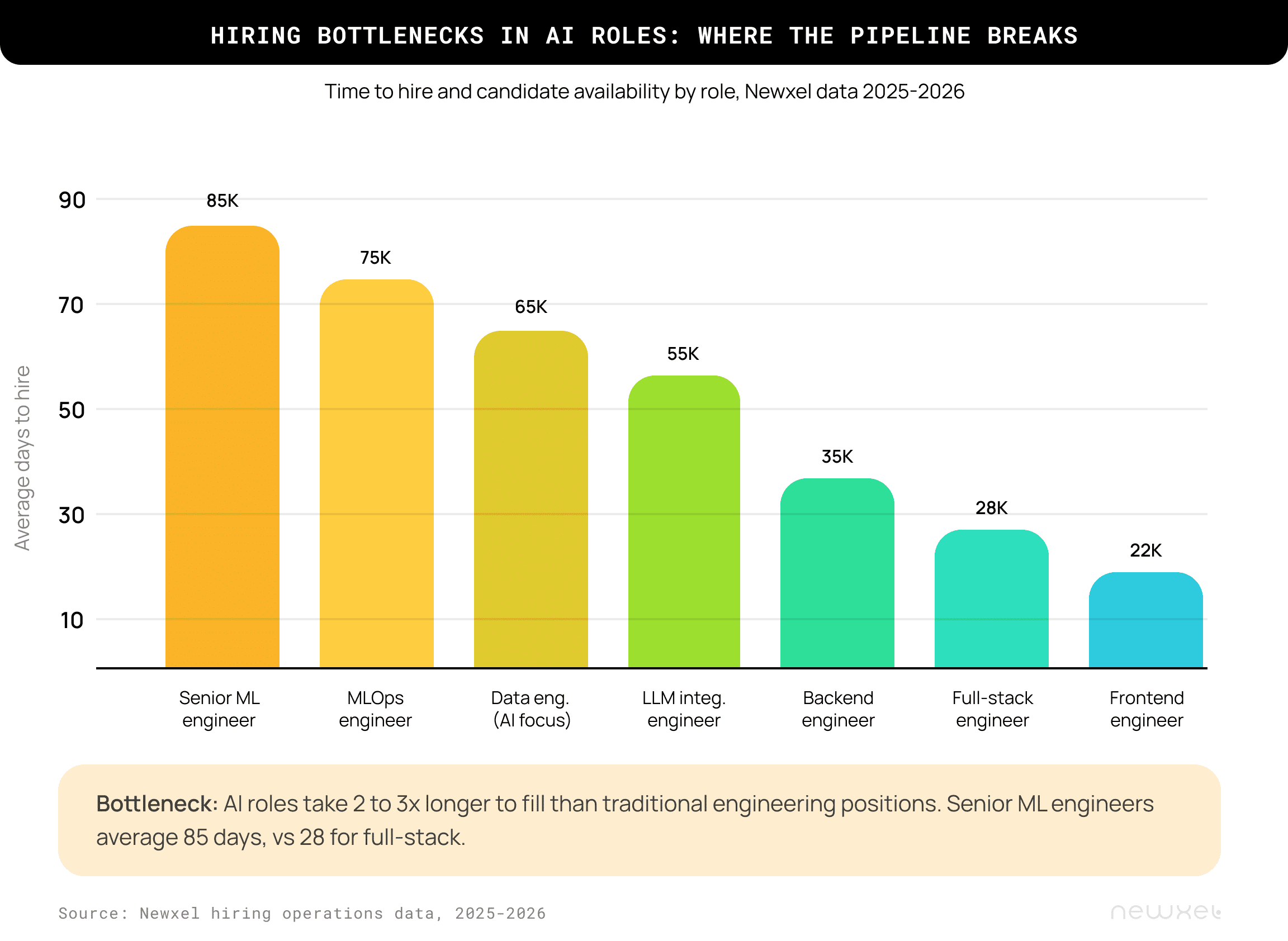
Three structural factors drive the gap.
The talent pool is small by the numbers. Only 205 AI PhDs were awarded in the US in 2022, and more than half of AI master’s and doctoral degrees were earned by non‑US citizens, which creates downstream visa complications. The global AI talent demand exceeds supply by roughly 3.2 to 1, depending on which labor market report you anchor to. That ratio means every company hiring for these roles is competing against well‑funded buyers with longer search timelines and more generous compensation bands.
Compensation is the second friction point. AI roles command salaries 67% higher on average than traditional software engineering positions, according to Glassdoor’s 2024 tech salary data. PwC’s 2025 Global AI Jobs Barometer found that workers with advanced AI skills earn up to 56% more than peers without those skills. Smaller product companies often can’t compete with Big Tech on these packages, which pushes them toward distributed hiring models where compensation expectations calibrate to regional markets rather than to San Francisco.
The third factor is the shelf‑life problem. The skills required to work in AI today look meaningfully different from what was considered sufficient two years ago, and the pace of change shows no sign of slowing. Experience becomes outdated quickly. That makes screening harder, because a candidate’s three‑year‑old ML project may tell you less about their current capability than their last three months of work.
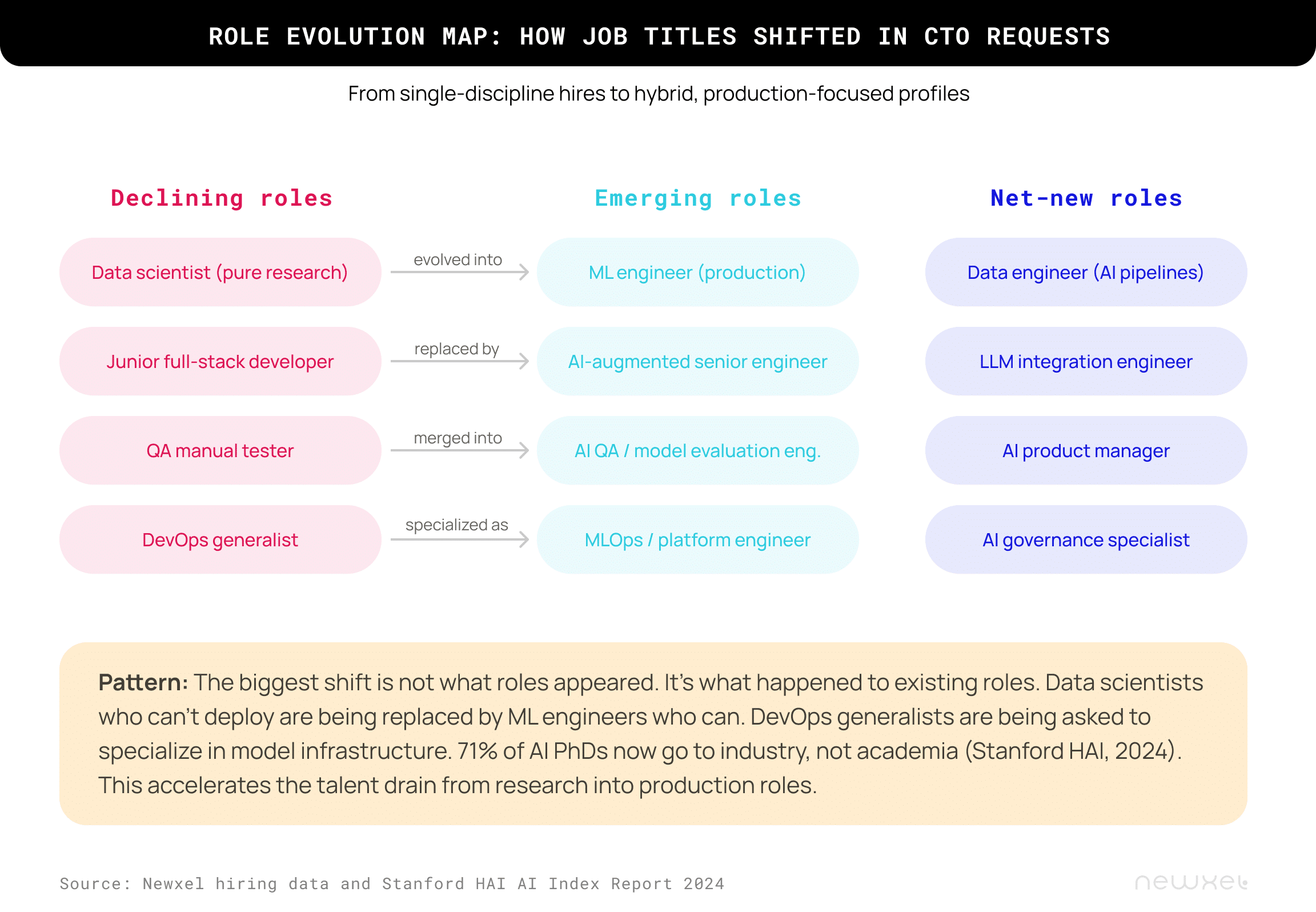
The shift isn’t only about new roles appearing. Existing roles have changed underneath the same job titles, which creates a more insidious hiring problem than the one CTOs usually notice.
Backend engineers are now expected to understand how to serve ML models through APIs, manage inference latency, and handle vector database scaling. DevOps engineers need to know about GPU orchestration and model deployment pipelines. QA roles are evolving toward model evaluation, bias testing, and drift detection. Even frontend engineers building AI‑powered features need more than React skill; they need to reason about streaming responses, token budgets, and user experience patterns for probabilistic outputs.
We had a client who posted a “senior backend engineer” role and couldn’t understand why candidates kept falling short of their bar. When we reviewed the job description, it included requirements for vector databases, embedding models, real‑time inference serving, and experience with LangChain. That was an AI infrastructure engineer hiding behind an old title. The company had written the job description by updating their standard backend template, adding the new requirements their product needed, and keeping the title that matched their internal pay band. The candidates they were rejecting were correctly matched backend engineers who lacked the AI‑specific skills that the real role demanded.
The framework we recommend now, when we see this pattern, is to audit any engineering job description that’s been updated more than twice in the last 18 months. If more than 30% of the required skills relate to AI infrastructure, it’s a different role. Rename it, reprice it, and source accordingly.
The geographic concentration of AI talent in a few cities (San Francisco, New York, London, Tel Aviv) makes local‑only hiring an expensive proposition for product companies that aren’t on a Big Tech compensation band. 82% of organizations have increased international AI hiring, per Deel’s 2026 data, and our intake volume reflects that shift directly.
Here’s what economics look like in practice.
Note on rates: figures in this section draw from two sources. Public compensation data for San Francisco roles is aggregated from Glassdoor, Levels.fyi, Built In, and Indeed (late 2025 and early 2026). Eastern European figures reflect Newxel’s internal pricing data from 8+ years of managing remote development teams across our European hiring hubs, cross‑referenced with public data from Alcor, Optiveum, and DNA325. Actual compensation varies significantly based on technology stack, seniority level, domain expertise, project complexity, and the specific country within each region. Niche specialists in AI, ML, LLM engineering, and MLOps typically command 20 to 40% premiums above general software engineering averages, and the premium widens in competitive markets. Fully loaded employer costs depend on how benefits, equity vesting, payroll taxes, recruiter fees, office overhead, and equipment are calculated. Treat these figures as directional benchmarks for planning, not fixed pricing.
A three‑person AI team in San Francisco (one senior data engineer, one senior ML engineer, one MLOps engineer) at fully loaded cost runs $720,000 to $1,000,000 per year. That figure includes base salary, bonus, benefits, equity vesting, payroll taxes, recruiter fees, office overhead, and equipment. The same team composition built through Newxel’s staff augmentation model in Eastern Europe, with equivalent seniority and English proficiency, runs $240,000 to $360,000 per year for the client. The total includes our fee, local payroll, taxes, benefits, HR, legal, and equipment. There’s no office overhead to add later because we handle facilities in our hubs.
Time‑to‑first‑candidate is the other variable that matters. Local ML engineer searches in our data average 85 days to close. Through our model, the first vetted candidates reach the client within 5 to 10 business days, and the first engineer typically starts work within 2 to 4 weeks. That gap compounds when you’re building a team of three or five. A local team build that takes six months compresses to six to eight weeks in the staff augmentation model.
The offshore argument for AI specifically is stronger than the offshore argument for traditional engineering, for two reasons. Compensation bands in Eastern Europe for AI roles have climbed, though the gap to US and UK pricing remains significant. The applied ML community in Kyiv, Krakow, Bucharest, and Sofia has matured faster than foreign CTOs expect. These cities host real ML meetups, local MLOps communities, and engineers who’ve shipped production AI for companies most CTOs have heard of.
The standard caveat applies. Offshore AI hiring only works if the partner actually vets for production skill rather than for keyword matches on a CV. The failure mode we’ve seen most often, in CTOs who tried offshore before coming to us, is hiring someone whose only ML experience is a coding bootcamp and a Kaggle medal. Vetting for this role category is harder than vetting for backend engineering, and it requires a partner who understands the distinction between someone who’s trained a model and someone who’s kept one running.
Across our 30+ clients, three team structure models account for essentially all the AI organizational designs we see. Each works at a different company stage and for a different AI maturity level. The choice matters, because structural mistakes are more expensive to fix than hiring mistakes.
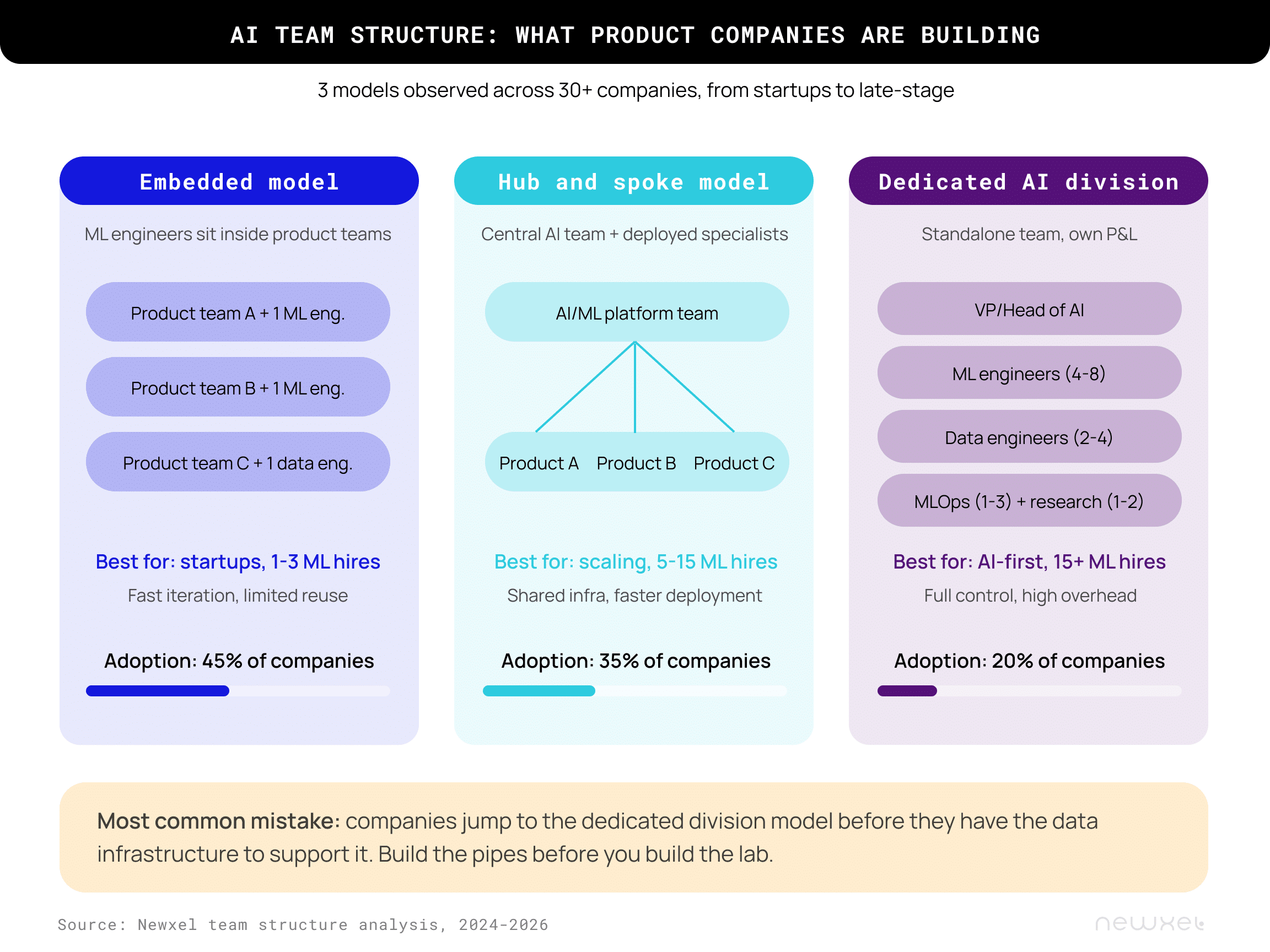
The split in our data: embedded models make up about 45% of AI team structures, hub‑and‑spoke sits at 35%, and dedicated AI divisions account for the remaining 20%. The trajectory over time runs in that order too. Companies start embedded, move to hub‑and‑spoke once they’ve cleared five to fifteen ML‑related hires, and graduate to a dedicated division only when AI becomes core to their product strategy and they have at least 25 AI‑adjacent engineers.
The embedded model puts ML engineers inside existing product teams, reporting to the same engineering manager who owns the product roadmap. It’s the fastest path from “we want to ship an AI feature” to “we shipped an AI feature,” with tight product alignment and clear priorities.
The failure mode is predictable. Knowledge locks inside a single team. The ML engineer builds their own tooling, their own feature pipelines, their own deployment scripts. When a second product team wants to build an AI feature, they have to start over rather than borrowing what the first team built. By the time a company has three or four product teams each running their own embedded ML work, the engineering organization is maintaining three or four incompatible ML platforms without realizing it.
This model works well for the first one to three AI hires and for companies where AI remains a feature rather than a core capability.
The hub‑and‑spoke model creates a central AI platform team that owns shared infrastructure (feature stores, model registries, experiment tracking, deployment pipelines, monitoring) while specialist ML engineers embed into product teams to do application work. The platform team handles the reusable pieces. The product‑embedded engineers handle the product‑specific work.
It’s the structure that most of our mid‑stage clients settle into by the time they’ve made their fifth AI hire. One of our clients, a cloud data infrastructure company, built a central ML platform team of four engineers in Eastern Europe that serves three product squads back in Tel Aviv. The platform team owns the deployment infrastructure and the feature store. The product‑embedded ML engineers build and iterate on models that use that infrastructure. The structure reduced their model deployment time from roughly three weeks to under five days once the platform was in place.
Prerequisites matter here. Hub‑and‑spoke requires that someone in engineering leadership wants to own the platform mandate and has enough political authority to make the product teams use it rather than building their own.
The dedicated AI division is its own unit with a VP or Head of AI, its own P&L, its own full team of researchers, engineers, and support staff. We see this structure in about one in five of our clients, almost exclusively at later‑stage companies or at AI‑first startups where the model itself is the product.
The biggest mistake we see in this category is companies attempting to jump to a dedicated AI division before they’ve built the data infrastructure that the hub‑and‑spoke model requires. You can’t run an AI division if your data pipelines are held together with cron jobs and CSV exports. The division’s researchers will spend their time fixing pipeline problems instead of building models, and the division’s credibility within the broader engineering organization will collapse inside 12 months.
The signal that a company is ready to make this transition is usually organic. The platform team inside the hub‑and‑spoke model grows beyond 15 people, the head of that team starts reporting directly to the CTO, and AI‑specific roles appear that don’t fit anywhere else in the org chart. That’s the moment, and not before.
The decision framework below summarizes when each structure fits.
| Structure | Best for | Team size | Prerequisite | Main risk |
| Embedded | First AI features, startups, product‑led teams | 1 to 3 ML engineers | None | Knowledge silos, duplicate infrastructure across teams |
| Hub‑and‑spoke | Multiple product teams needing AI capability | 5 to 15 ML‑related hires | Engineering leadership mandate for a shared platform | Platform team undervalued or bypassed by product teams |
| Dedicated AI division | AI as core product, later‑stage scaleups | 25+ AI‑adjacent engineers | Mature data infrastructure, established MLOps practice | Division becomes isolated from product reality |
Not everything shifted. A few things stayed constant, and they’re worth naming because missing them causes hiring failures that look like AI‑specific problems when they really aren’t.
Seniority requirements didn’t decrease. If anything, the bar went up. Most AI positions in our data require two to six years of experience minimum. Companies aren’t hiring junior ML engineers and training them. They’re hiring seniors and hoping those seniors can also teach the existing team, which is a lot to ask from one role. The industry‑wide preference for senior talent is a real barrier for companies whose compensation bands cap out below the senior AI market.
Communication skills still matter, arguably more than before. AI projects involve more cross‑functional coordination than most software work, because stakeholders need help understanding why a model’s accuracy dropped by 3% last week and whether that’s a problem. CTOs consistently tell us they want ML engineers who can explain what they’re doing to non‑technical stakeholders without either oversimplifying or condescending.
And the fundamentals haven’t gone away. Python, SQL, cloud platforms, Git, system design basics. Every AI role we place still requires the core engineering competence that was expected five years ago. The new skills stack on top. They extend the baseline rather than replacing it.
For CTOs who’ve decided to build their AI capability through a distributed model, the first 90 days determine whether the engagement delivers or drifts. Here’s what the sequence looks like in practice.
Weeks 1 and 2 are about scoping and role definition. This is where we spend the most time in AI engagements, and it’s also where most offshore AI team builds fail when the partner skips this step. We work through the client’s AI maturity honestly: what data infrastructure exists, what ML has shipped to production so far, what the product roadmap requires in the next six months. From that we translate the client’s initial role list into an actual hiring plan. This is where we regularly suggest cutting five ML engineers down to two data engineers plus one ML engineer, and explain why.
Weeks 2 through 4 cover sourcing and first candidates. Our hiring hubs run continuous sourcing pipelines for AI roles, so the first vetted candidates typically reach the client within 5 to 10 business days of the kick‑off call. Vetting for AI roles goes deeper than for traditional engineering. Our four‑step process includes technical interviews with existing ML engineers in our network, practical exercises that require production‑shaped thinking rather than research exercises, and communication screens designed to surface how the candidate handles ambiguous product requirements.
Weeks 4 through 8 are about onboarding and integration. This phase differs from traditional engineering onboarding in three ways. First, access to training data and GPU infrastructure has to be arranged before the engineer arrives, because AI engineers can’t contribute without both. Second, experiment tracking tools and model registries need to be set up or documented so the new hire can plug into existing workflows rather than starting from scratch. Third, the first two weeks should include shadowing an existing ML engineer or data engineer if one is already in the organization. Otherwise the new hire spends three weeks figuring out the local conventions instead of shipping.
Weeks 8 through 12 are when full velocity arrives, which we define as reviewed and merged code in production workflows. For traditional engineering hires, we expect merged code in week 2 and full velocity by week 6. AI roles run longer because the setup is heavier. By week 12, an ML engineer should be owning at least one production model end to end. If they aren’t, something in the onboarding broke, and it’s worth investigating before the cycle repeats with the next hire.
If you’re a CTO or VP of engineering trying to build AI capability in 2026, our data suggests four practical moves.
Start with data infrastructure. Hire data engineers before ML engineers. Companies that invested in their data layer first had significantly easier times hiring and retaining ML engineers later, because those engineers had something to work with on day one. The ones who hired ML engineers first ended up with frustrated expensive hires who spent six months fixing pipelines instead of building models. Budget for two data engineers before your first ML engineer, unless you already have a clean, documented data platform.
Plan for longer hiring timelines. AI roles take two to three times longer to fill than traditional engineering roles. If you need a senior ML engineer contributing by Q3, start the search in Q1. If you’re building a team of three, start a quarter earlier than you would for equivalent traditional engineering hires.
Consider distributed and offshore models seriously. The geographic concentration of AI talent in a handful of cities has made local‑only hiring structurally expensive. Our clients in Israel, the US, and the UK are building dedicated AI teams through our Eastern European hubs because the talent density is real and the competition intensity is lower. Three to four years ago this was a cost optimization. In 2026 it’s often the only viable path to a full AI team inside a year.
Be honest about what you need versus what you think you need. The difference is usually two to three headcount. We regularly talk CTOs down from “we need a team of five ML engineers” to “you need two data engineers and one ML engineer.” The sequencing matters more than the headcount.
For software engineers wondering where the market is heading, our data points clearly in one direction. Production ML skills are the highest‑leverage addition to your toolkit right now. Deployment experience is in shorter supply than research talent, and the compensation bands reflect that gap.
MLOps is the fastest‑growing role category we track, and it’s accessible to experienced DevOps and platform engineers who pick up ML‑specific tooling. The MLOps market is expected to reach $5.9 billion by 2027, up from $1.1 billion in 2022, per third‑party market sizing we’ve cross‑checked against our own placement data. If you have infrastructure experience and can learn MLflow, Kubeflow, feature stores like Feast or Tecton, and model serving platforms, you’re positioned for the role category with the strongest demand curve.
Data engineering skills are becoming a prerequisite for data scientists, and the boundary between the two roles is dissolving faster than most engineers realize. Recent analysis showed SQL requirements in data science postings increasing by 18 percentage points year over year. If you’re a data scientist who can’t write production SQL against a Snowflake or BigQuery warehouse, the market is telling you something.
The compensation reflects all of this. AI‑skilled engineers earn up to 56% more than peers without those skills, per PwC’s 2025 AI Jobs Barometer. The premium is largest for production ML and MLOps, smallest for pure research.
We’ve been building engineering teams for product companies since 2017. The AI shift is the most significant change we’ve seen in hiring behavior since the cloud migration era, and it’s still early.
What stands out in our data isn’t the demand for AI skills in aggregate. It’s the persistent gap between what CTOs think they need and what they need in practice. Most product companies aren’t building their own foundation models. They’re integrating AI into existing products. That means they need engineers who can work with APIs, manage data pipelines, and handle the operational complexity of running ML in production, more than they need researchers writing novel architectures.
Our role in the engagement has shifted accordingly. We spend more time helping CTOs define what they’re looking for, mapping AI maturity to the right hiring sequence, and sourcing from talent pools that traditional recruiters don’t reach. The candidates exist. They’re in Kyiv, Krakow, Bucharest, Sofia, Warsaw, and Lisbon, often at companies most CTOs outside the region haven’t heard of. The challenge is matching them to the right roles at the right time, which is mostly a scoping problem rather than a sourcing problem.
The companies that get the sequencing right will have a structural advantage for the next five years. Most are only now starting to build.
AI changed what CTOs ask us to hire. It also changed how they think about team composition, where they source talent, and what “ready to contribute” means for a new engineer. The old playbook, which was to hire full‑stack engineers and figure out the rest later, stopped working.
For the companies that get the sequencing right (data infrastructure first, then MLOps, then research if the product demands it), the talent is there. It takes longer to find, costs more than it used to, and requires looking beyond the obvious geographies. The companies building these teams now are still early, which is why the structural advantage is available.


