What is Distributed Development: Business Owners’ Guide
19 min
· March 3, 2023

A practical guide for CTOs, engineering leaders, and founders building software teams across geographies. Written based on Newxel’s direct experience managing distributed development teams since 2017 across 8 European hiring hubs.
Think of distributed software development as a borderless digital office.
In this setup, your team isn’t gathered around a single coffee machine; they’re scattered across time zones and kitchen tables. You might have a backend wizard in Krakow, a frontend pro in Bucharest, and a product lead in San Francisco. They won’t be grabbing lunch together anytime soon, but they’re constantly collaborating in the same code repository and debating the same pull requests.
It’s a far cry from traditional outsourcing. Instead of just handing a checklist to a vendor and waiting for the “finished” product, you’re building a singular, cohesive team that just happens to be miles apart.
In a distributed model, engineers are part of your team. They join your standups, argue in sprint planning, and accumulate institutional knowledge about your product over years. The distribution is geographic. The integration is complete.
Ten years ago, most distributed setups ran into the same wall: the tooling wasn’t there yet. Video calls dropped, shared dev environments didn’t exist, and half the team’s energy went into coordinating instead of building. That’s changed. Async communication platforms, cloud-based dev environments, and CI/CD automation have closed most of the gaps that made distributed work feel like a downgrade. The market reflects this: global software development spend is tracking from $640 billion in 2026 toward $1.11 trillion by 2031. That growth is disproportionately driven by companies that stopped treating distributed engineering as a contingency plan and started running it as their default.
Everything starts with specificity. Not “we need developers” but “2 senior backend engineers with production Go and Kubernetes experience who can overlap with San Francisco between 9am and 1pm Pacific.” If your requirements read “we need developers,” you’ll get candidates who are technically developers but wrong for your codebase, your architecture, your team culture. In a distributed setting, that mismatch takes longer to become obvious because nobody’s sitting close enough to notice the early warning signs.
The workflow piece catches most companies off guard. Co-located teams resolve ambiguity by walking over to someone’s desk. Distributed teams post a question in Slack and wait 3 hours for a reply because the person who knows the answer is 7 zones away, eating dinner with their family. The teams that handle this well don’t try to replicate the co-located experience. They design around written communication, documented decisions, and enough self-service context that a developer in Krakow can start their morning exactly where New York left off.
And the management shift is real: you stop tracking hours and start tracking throughput. Stories completed, PRs merged, features in production. This is a harder adjustment for engineering leaders than most admit, because it requires trusting processes over presence.
Embedding individual contributors into existing teams is the simplest approach. A frontend specialist in Lisbon joins an established squad, stepping into the same Jira boards and sprint rhythms. This works for a specific skill gap, but coordination tax across 3 or more time zones eats into productivity quickly.
A pod of 4 to 6 engineers sitting together in one location owns a specific product domain end to end. Because they’re physically close, they still get to whiteboard through problems, grab each other for quick pairing sessions, and make fast decisions within the pod. The connection to the broader org runs through documented APIs and interface contracts rather than meetings. This is the model we recommend to most clients.
Full distribution removes the “main office” entirely, eliminating the information asymmetry that quietly undermines hybrid setups. This demands the highest commitment to documentation and operational discipline, but when it works, there’s no “second class” team.
One pattern across hundreds of engagements: keep pods small, mirror system architecture with team architecture, and make ownership unambiguous.
Talent access is the reason most companies come to us, and it’s the most defensible one. Across our 8 hiring hubs, we consistently source engineers with deep expertise in AI, ML, and cloud architecture from a regional talent pool of over 3.5 million ICT specialists in Eastern Europe.
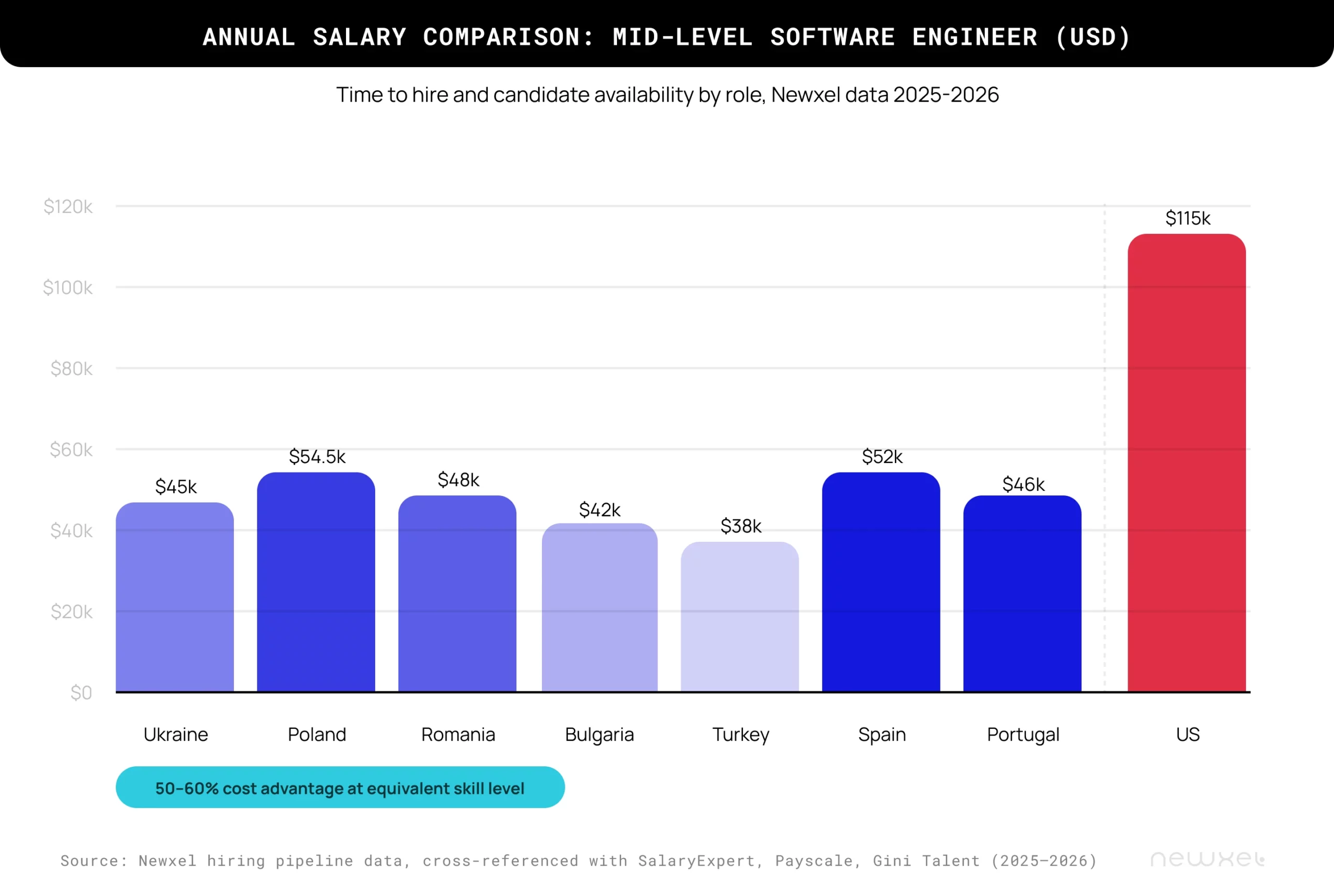
The numbers we see in our hiring pipeline show mid-level engineers in Poland or Romania at $48,000 to $54,500 annually. The equivalent US role costs $110,000 to $120,000. But we’ve seen what happens when companies chase the absolute cheapest rate: they get engineers who are cheap for a reason. The advantage works when you pay market rates in a region with lower living costs.
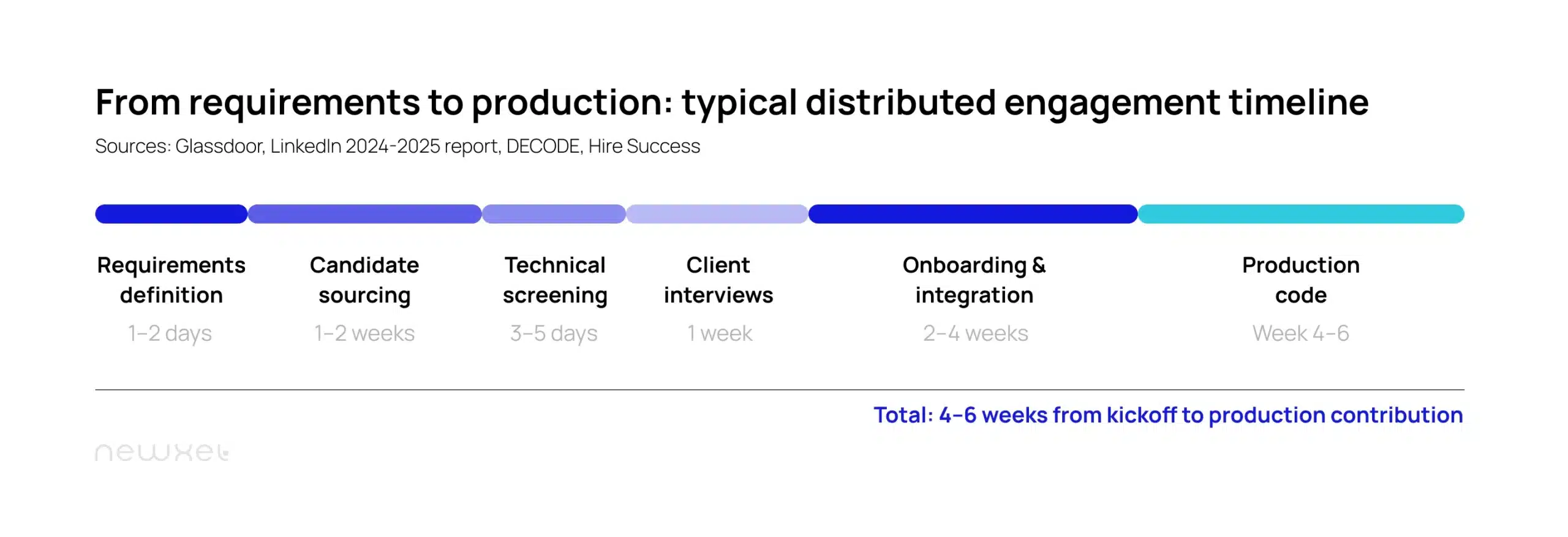
Speed often tips the decision. Through our pipeline, clients review vetted candidates in 2 to 3 weeks and see production code contributions by week 4 to 6. Domestic hiring for a senior engineer takes 3 to 6 months. If your company burns $500,000 a month and needs 8 more engineers this quarter, that gap translates to hundreds of thousands of dollars.
Distributed teams also give you near-continuous coverage. A bug filed at 5pm Eastern gets investigated before anyone in the US wakes up. The product moves forward while portions of the team sleep.
Adopting this model means accepting a set of trade-offs. The failures we see at Newxel almost never come from the model itself. They come from teams that assumed co-located processes would transfer without adaptation.
“Communicate more” is the wrong answer. More messages, more meetings, more notifications make things worse. What works is communicating differently: reserving synchronous time for high-ambiguity conversations and running 70 to 80% of information flow through written async channels where reasoning gets documented and becomes searchable.
One practice we’ve seen prove more valuable than any other: converting the daily standup from a video call into a written, async format. Each contributor posts what they completed, what they’re pursuing, and what’s blocking them. The PM scans it in 3 minutes.
The cultural friction tends to cluster around 3 areas, and all of them are solvable once you name them. Directness is the first: some engineers will tell you bluntly when an approach won’t work, others will express the same disagreement by asking a series of questions that imply the problem without stating it. Code review hierarchy is the second: in some cultures, a junior developer who spots a bug in a senior’s code will flag it immediately, in others, they need a formal channel or they’ll stay quiet. Deadline philosophy is the third, and it’s subtler than the other two. The fix is making these implicit assumptions explicit during onboarding, not hoping people figure it out through osmosis.
What happens in practice: the main team updates a quality standard in a retrospective, someone mentions it on a call, and the co-located engineers absorb it through proximity. The pod in another country never hears about it and keeps building to the old spec. Fast-forward three months and you’re staring at two different solutions for the exact same problem. It’s frustrating, but it happens.
The fix isn’t flashy, but it works: you bake linters, formatters, and static analysis right into your CI/CD pipeline. This way, the code standards hold themselves up. You don’t have to rely on everyone perfectly remembering every takeaway from a meeting three weeks ago; the system catches drift before it becomes a problem, so the team can focus on building.
They’re solving problems through their own reasoning, which is exactly what you hired them to do, except now their reasoning is diverging from the main team’s without anyone noticing. A few months in, you discover two different error-handling philosophies living in the same codebase. The countermeasure is cultural, not technical: Architecture Decision Records that explain the “why” behind patterns, code review treated as mentorship rather than gatekeeping, and a biweekly session where the whole team walks through a non-trivial piece of code together. Not to catch bugs. To keep the engineering philosophy unified.
In a co-located team, knowledge spreads through overheard conversations and casual whiteboarding. In a distributed team, tribal knowledge becomes a liability. If important context exists only in one person’s head, it’s unavailable to everyone in other locations. Documentation has to be load-bearing infrastructure: PR descriptions, sprint summaries, architecture decision records, post-incident reviews. The test: if a piece of knowledge is needed to do the job, someone should find it by search in under 2 minutes.
The Agile Manifesto was written in 2001 by people sitting in the same ski lodge. “Face-to-face conversation is the most efficient method” made sense when the alternative was email threads and conference calls that cut out every 30 seconds. The principles underneath, short feedback loops, continuous adaptation, shipping working software instead of writing documents about software, those don’t require physical proximity. They require discipline.
Sprint planning works better when you split it: the product owner publishes stories with acceptance criteria async, the team estimates and raises questions in threads during their own hours, then a short synchronous session handles whatever’s still unresolved. Daily standups go written. Reviews and retrospectives stay synchronous because feedback loses too much nuance in text. Backlog refinement often improves in distributed setups because engineers across locations bring perspectives a homogeneous co-located team misses.
One principle worth stating plainly: in distributed agile, write everything down. A decision made in a hallway at the office spreads to 20 people by lunch. In a distributed team, an undocumented decision is an invisible decision. The discipline this forces tends to make engineering organizations better, not worse.
There’s no shortage of tools that claim to solve distributed development. The real challenge is building a toolchain where each component serves a clear purpose and information flows between them without manual intervention. You need coverage across 7 categories:
| Category | Recommended tools | Why it matters for distributed teams |
| Real-time communication | Slack, Microsoft Teams | Channel-based async messaging with searchable history |
| Video conferencing | Zoom, Google Meet | Reliability for synchronous touchpoints across time zones |
| Project management | Jira, Linear, Asana | Single source of truth for sprint state visible to all locations |
| Version control & DevOps | GitHub, GitLab, Bitbucket | CI/CD pipelines that enforce quality gates automatically |
| Documentation & knowledge | Confluence, Notion, GitBook | Searchable knowledge base replacing hallway conversations |
| Cloud dev environments | GitHub Codespaces, Gitpod | Eliminates local setup friction for distributed engineers |
| Async video | Loom, Vidyard | Explains complex logic without scheduling a meeting |
The tool matters less than the practice. A team using Notion with strong documentation habits will outperform a team using Confluence with a culture of “I’ll just tell you on the call.” If you had to pick one category to invest in first, make it DevOps automation. When your CI/CD pipeline enforces formatting, testing, and deployment standards on its own, you eliminate an entire class of problems that would otherwise require someone to coordinate across time zones.
In a co-located team, communication defaults to synchronous and documentation happens when someone gets around to it. In a distributed team, those defaults invert. Written async channels carry the bulk of daily work, and documentation becomes the primary mechanism for organizational memory.
Imagine your team’s communication as three concentric rings, each serving a different purpose for keeping everyone in sync.
The innermost ring is your team’s permanent record: platforms like Notion or Confluence where your blueprints, big decisions, and process guides live. These aren’t documents that change every hour, but they’re vital. When a teammate is stuck, they should be able to find the answer here in under two minutes.
The middle ring is where the daily grind happens. It’s the steady hum of Slack or Teams, threaded conversations and quick updates where the team coordinates in real time. It’s searchable, fast, and keeps the project moving without a meeting.
The outer ring is for synchronous moments: the scheduled video calls for sprint ceremonies or 1:1s. This ring is reserved for sensitive feedback, brainstorming, or those messy, ambiguous conversations where you need to see a face to catch the nuance that text can’t capture.
Social connection deserves its own layer. A #watercooler channel, monthly show-and-tell sessions, and virtual coffee pairings. People who know each other personally give more generous readings to ambiguous Slack messages and resolve friction faster.
The math works out well for Western companies. Poland, Romania, and Bulgaria sit in CET/EET zones, which translates to 6 to 8 overlapping hours with the UK and 4 to 6 with the US East Coast. That’s a healthy enough window for a full sprint ceremony and a few quick “hey, got a second?” calls without forcing anyone to work at midnight.
Think of these overlapping hours as your team’s most valuable resource. Save them for the stuff that usually falls apart in text: those messy architecture debates where you need to think out loud, disagreements that might spiral on Slack, or any sensitive feedback where hearing a friendly tone of voice makes all the difference.
Everything else goes async. If you schedule meetings for every overlapping hour, you’ve eliminated the only time your distributed team can collaborate live, and you’ve given them no deep work time either.
One often-overlooked benefit: incident response coverage. When production goes down at 3am Eastern, the engineering team in Krakow is already at their desks. Distributed coverage means faster mean time to resolution and fewer 3am pages for your US-based engineers.
Compensation strategy for distributed teams sits at the intersection of local market rates, perceived fairness, and retention. Get it wrong and your best engineers leave for a company that values them properly.
We benchmark salaries against local market data in every hub. Paying at or above the 75th percentile for the region ensures you’re not competing on employer brand alone. A mid-level engineer in Poland earning $54,500 is well-compensated locally, even though it’s half the US equivalent. That salary gap is where the cost advantage lives, and it only holds if the engineer on the other end feels the compensation is fair for their market. The moment they don’t, your retention disappears.
Tying a portion of pay to measurable outcomes (team-level OKRs, sprint velocity, product metrics the whole company tracks) creates alignment you can’t get from base salary alone. We’ve seen quarterly structures tied to team goals produce stronger engagement than individual-only incentives, because they reinforce the collaboration habit across the project.
Distributed engineers are invisible by default. When a feature ships, the co-located team gets spontaneous recognition. The developer in Bucharest who wrote the core logic gets nothing unless someone deliberately includes them. Make distributed contributions visible: public shoutouts, shared credit, inclusion in product announcements. It costs nothing and affects retention directly.
After managing distributed teams since 2017, we’ve distilled our operational experience into practices that consistently separate strong engagements from mediocre ones. The underlying philosophy: measure output, not hours. Engineers who feel trusted to manage their own time produce better work than those micromanaged across zones.
Here’s the counterintuitive part: virtual onboarding needs to be more structured than in-person, not less. When someone joins in an office, they absorb context by sitting near the right people. A distributed engineer doesn’t get any of that for free. In a remote setup, context doesn’t just “happen” by accident. You have to hand-deliver it. To make that work, we structure a new hire’s first 90 days with clear, weekly milestones and pair them with a buddy in a similar time zone, so there’s always someone to ask. Then, we stay close with intentional check-ins at the Day 7, 14, 30, 60, and 90 marks. At Newxel, we split this into two tracks: the client owns the technical side (codebase walkthrough, architecture context, product priorities), and we handle operations (equipment, access setup, working norms).
Face-to-face time is the glue that keeps everything from becoming transactional. Without those regular touchpoints, engineers can start feeling like they’re working in isolation, and that kind of disconnect erodes morale faster than a messy codebase ever could.
The minimum cadence that works: daily written standups for quick alignment, a weekly video sync of 30 to 45 minutes, biweekly sprint ceremonies to keep the project on track, and monthly 1:1s for deeper support. And if the budget’s there, nothing beats flying everyone to the same city once a year. The shared experience of grabbing a real-world coffee together makes the digital work noticeably smoother for the rest of the year. Every client who does this tells us the same thing: cohesion improves and turnover drops in the quarters that follow.
Shared goals prevent the failure mode where co-located engineers become the “real” team and distributed engineers become task-ticket recipients. Give everyone the same OKRs, the same product metrics, and enough context to understand why features are prioritized. When a sprint goal says “reduce checkout abandonment by 15%,” every engineer should understand that number.
If a decision is worth the time to discuss, it’s worth the time to write down. In a distributed world, if it isn’t documented, it basically didn’t happen: it becomes invisible to anyone who wasn’t in the “room.”
To keep things moving without burning everyone out, be explicit about response times. For urgent messages like production crashes or total blockers, aim for a 30-minute turnaround. Standard day-to-day questions get a 4-hour window. Longer async discussions deserve one business day for a thoughtful reply.
Setting these boundaries means your team doesn’t have to live in their inbox, but they also never feel ignored. And match the medium to what you’re communicating. Quick factual questions belong in Slack. Complex technical debates belong in PR threads or doc comments. Anything sensitive, performance feedback, disagreements, compensation, belongs on a video call where tone of voice does half the work.
A #random Slack channel, monthly show-and-tell sessions, acknowledging cultural holidays across all locations. The key word is “optional.” Mandatory fun backfires. Create the space and the invitation. The people who participate build real connections, and those connections benefit the whole team’s collaboration when work gets hard.
The practical differences show up across every dimension that matters to engineering leadership, and they compound over 6 to 12 months. Outsourcing works for bounded projects with a clear endpoint. Distributed development is what you need when the work is ongoing, the product knowledge needs to compound, and you can’t afford to lose engineering control.
| Dimension | Outsourcing | Outstaffing | Distributed development |
| Who manages the team | The vendor | You | You |
| Knowledge retention | Leaves with vendor | Stays with your org | Stays with your org |
| Team continuity | Vendor rotates engineers | Dedicated to your team | Dedicated, with local co-location |
| Quality model | Inspect-and-defend at handoff | Shared standards, integrated review | Shared standards, CI/CD enforced |
| Cost model | Fixed-price or T&M with PM layer | Transparent per-engineer rate | Transparent per-engineer rate |
| Best for | Bounded projects outside core product | Scaling with individual hires | Ongoing product engineering |
Outsourcing makes sense for bounded, well-defined projects that sit outside your core product. Distributed development is what you need for ongoing product engineering where continuity, deep knowledge, and engineering control matter.
What we do is own the entire operational layer of building and running an international engineering team, from the first candidate search through years of ongoing employment. We’re not a recruitment agency that sends a stack of resumes and moves on to the next client.
We hire across 8 European locations (Ukraine, Poland, Romania, Bulgaria, Turkey, Spain, Portugal, Israel), screening through technical evaluation by our in-house engineers, English proficiency checks, and cultural fit mapping specific to your team’s norms. Engineers who fail in distributed engagements almost never fail on technical ability. They fail on communication fit. Our process catches that early.
We act as Employer of Record: contracts, payroll, taxes, benefits, equipment. For UK clients, our EOR model eliminates IR35 risk because engineers are our full employees. You get a service agreement with Newxel. We handle everything else.
Our 98% retention rate means engineers stay, and the knowledge they build compounds. Average client relationships run 5+ years. We see a recurring pattern: clients come after an outsourcing engagement that became frustrating, or after 6 months of dry domestic pipelines. The underlying need is always the same: engineers who are part of the team, who understand the product deeply, who stay, and who come wrapped in a partner structure that handles international employment invisibly.
Distributed software development stopped being an experiment a while ago. Thousands of companies run distributed engineering organizations as a permanent operating model. The companies that succeed invest in communication infrastructure early, design team structures around their product architecture, codify quality standards and enforce them through automation, and work with partners who understand that placing the engineer is step one of a longer process.
If you’re weighing whether distributed development fits your setup, we can walk you through a specific engagement: timeline, cost structure, available talent for your stack. The conversation takes 30 minutes.


